
※アイトリガーとNF-Xは2021年6月1日に合併しました。本記事は合併前に執筆したものです 。
※スクレイピングに関しては、個人の情報分析で利用する場合は基本的に問題ありませんが、NGとなる場合もあるので、自己責任でお願いいたします。
こんにちは。突然ですが「自社の競合サイトを調べたい!」というとき、どうしていますか?
例えば、自社の競合サイトを調べたい!というとき、普通の人であればGoogle(or Yahoo)で検索し、一つ一つのサイトにアクセスして「ふむふむ、なるほど…」とか言いながらエクセルなどでまとめていくのではないでしょうか。
今回紹介する「スクレイピング」という方法なら、一つ一つまとめていく必要はありません。
Web上でスクレイピングとは、簡単に言うと必要な情報を抽出することです。
スクレイピングって聞くと、横文字で難しそう…と言う印象を抱きがちです(私も昔そうでした)が、実はそんなに難しくありません。
スクレイピングは本来、プログラミングの知識を有する人でないとできませんが、プログラミングの知識がなくても、スプレッドシートで簡易的ではありますがスクレイピングが可能です。
今回は、スプレッドシートでスクレイピングを可能にする「IMPORTXML関数」について、これから使い方や具体的な活用方法をご紹介していきます。
その他のスプレッドシートの関数は以下の記事にまとめております。


IMPORTXML関数の仕組み
IMPORTXML関数は、サイトから必要な情報を指定し、その部分の情報をスプレッドシートに出力できるような関数です。
似たようなものにIMPORTHTML関数が存在しますが、本記事では、IMPORTXML関数に絞って説明します。
まずは、IMPORTXML関数の構文からご紹介します。
IMPORTXML(URL,XPathクエリ)
おそらく、これだけ見るとXPathクエリ?どう使えばいいかわかんない!ってなるかと思うので、ここから深堀りしていきます。
URLに関してはほとんどの人がご存じかと思いますが、ページ上部に表示される英数字や記号が羅列された部分です。
例えば弊社のHPだと、「https://aitrigger.co.jp/blog/」の箇所になります。

次に、XPath(エックスパス)についてですが、マークアップ言語XMLに準拠した文書の特定の部分を指定する言語です。
これは言葉では理解が難しいと思うので、「そういうものがあるんだな」くらいで大丈夫です。
※以後、Google Chrome上での作業を想定していますので、他ブラウザを使用される場合は挙動が異なる場合がございます。
XPathの取得方法
実際に、XPathを取得してみましょう。
今回は、一番上にある「サービス」という箇所のXPathを取得してみます。
サービスの部分を右クリックし、「検証」をクリックします。
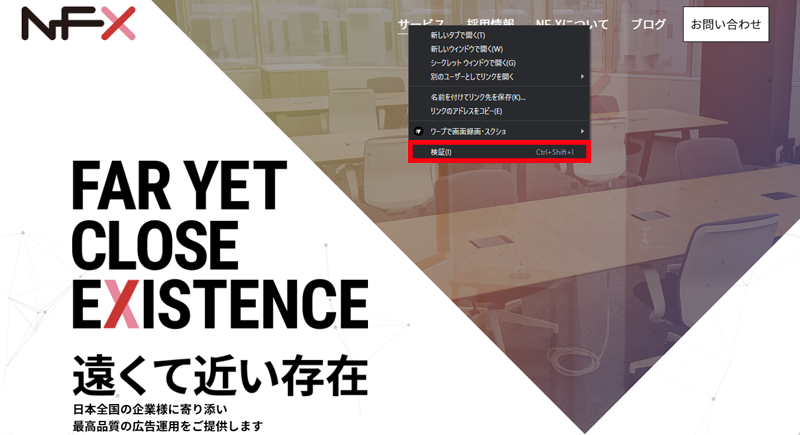
すると下のような画面になり、右側にソースコードの羅列みたいなものが出てきたかと思います。
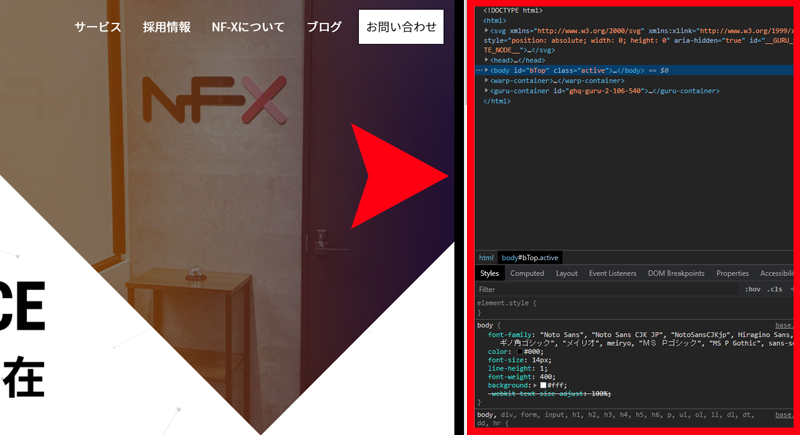
続いて、右側の部分を触っていきますが、青く塗られている記述の部分があります。
今回で言うと、「<a href=”/service/”>…</a> == $0」の箇所です。
(「…」の部分は省略されています。実際にはサービスという文言が記述されています)
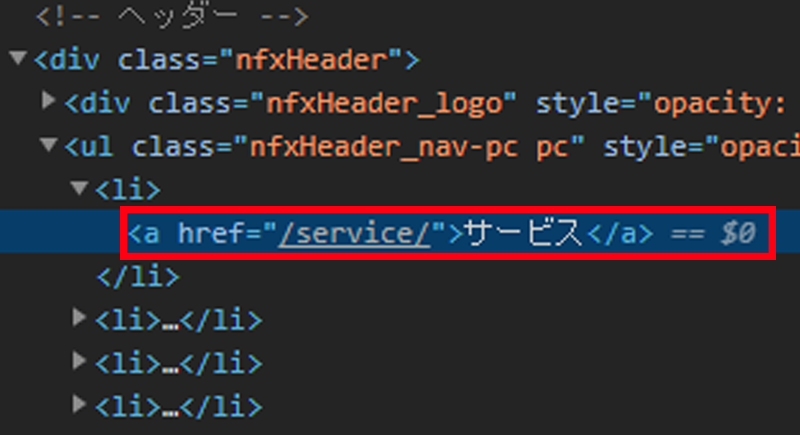
こちらにカーソルを合わせて右クリックし、「Copy>Copy XPath」を選択します。
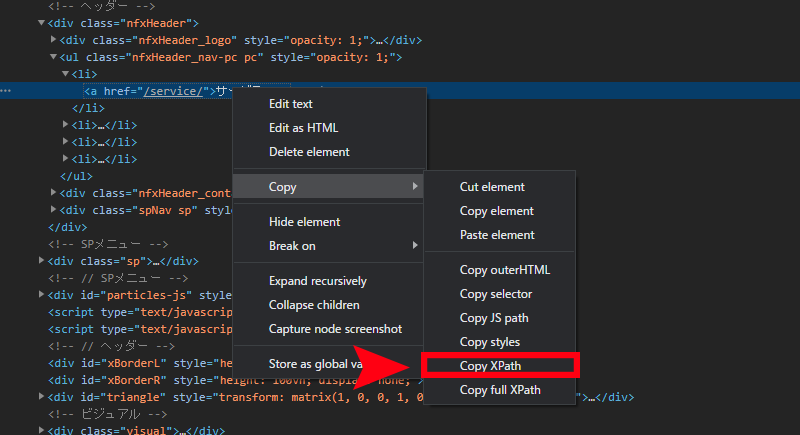
コピーして、貼り付けていただければ、「//*[@id=”nfx”]/div[1]/ul/li[1]/a」というXPathが取得できていることがわかります。
スクレイピングの方法
では実際に、Googleスプレッドシートを使ってスクレイピングをしてみましょう。
まずは、スプレッドシートを準備しましょう。既存のスプレッドシートでも大丈夫です。
次に、出力したい箇所をアクティブにし、IMPORTXML関数を入力します。
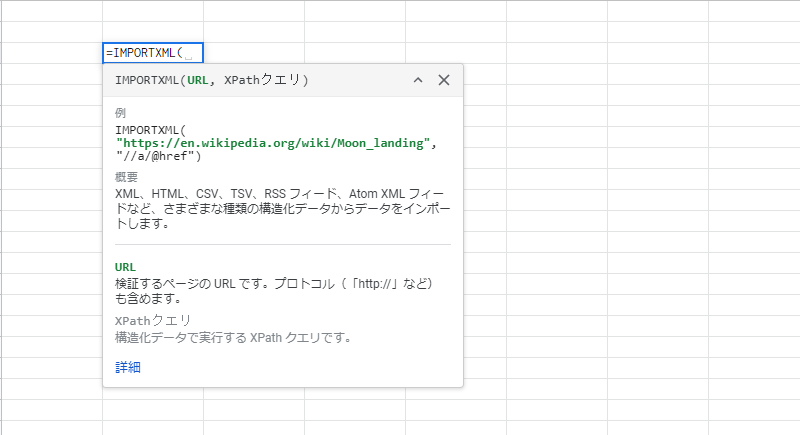
続いて、URLを入力しましょう。
今回元にしたのは弊社のHPURLなので、「https://aitrigger.co.jp/blog/」をダブルクォーテーション「”」で囲って入力します。
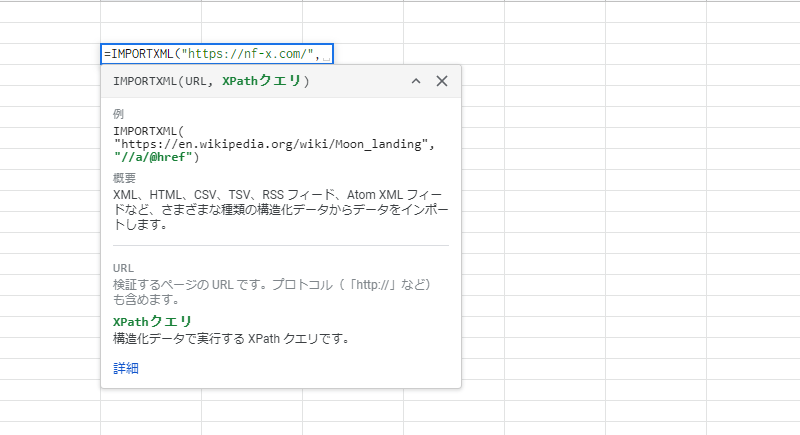
続いて、先ほどコピーして取得したXPathを入力します。こちらもダブルクォーテーション「”」で囲みます。
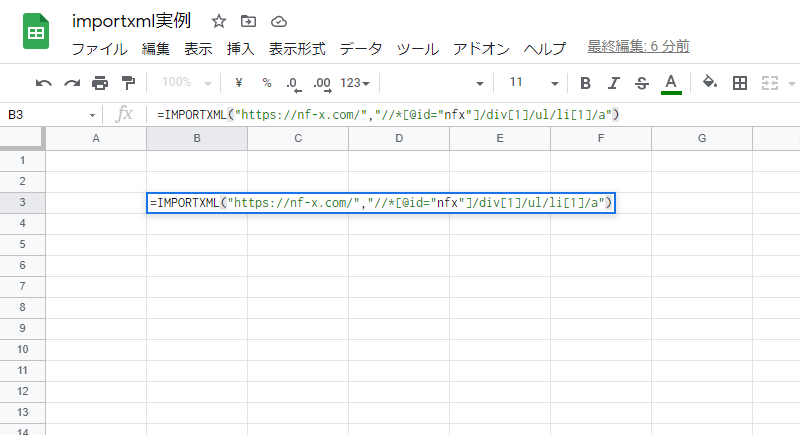
これで、関数の入力ができましたが出力結果は「エラー」。ルールに従って入力したはずなのに、なぜだと思いますか?
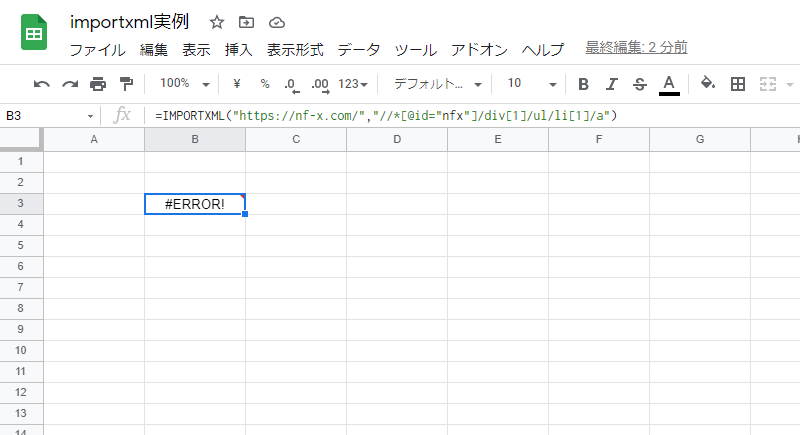
実は、問題があるのはXPathの部分です。
先ほど、ダブルクォーテーションで囲むということをお伝えしましたが、それだけではダメでした。
なぜなら、「[@id=”nfx”]」の「”nfx”」の部分をダブルクォーテーションで囲っているからです。
本来ならば、XPathすべてをダブルクォーテーションで囲む必要があったのですが、XPath内にダブルクォーテーションが使われていて、途中でXPathが途切れるという判定になってしまいます。
なので、この場合は「”nfx”」のダブルクォーテーションをシングルクォーテーション「’」に変えてあげましょう。
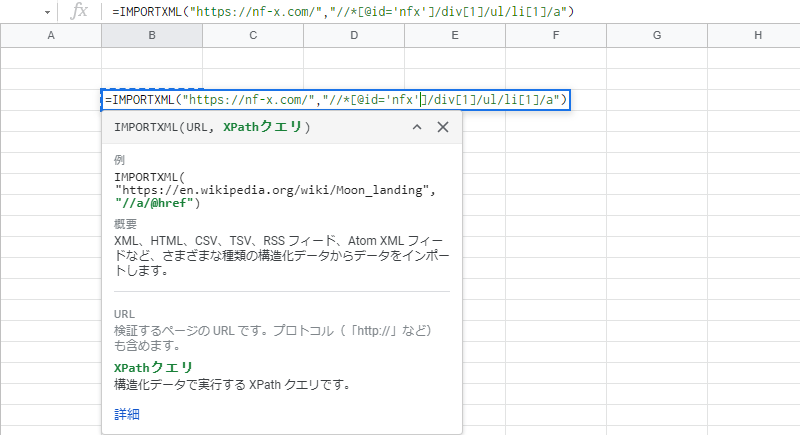
すると、全てのXPathが緑色になり、1つの文字列として認識してくれるようになりました。
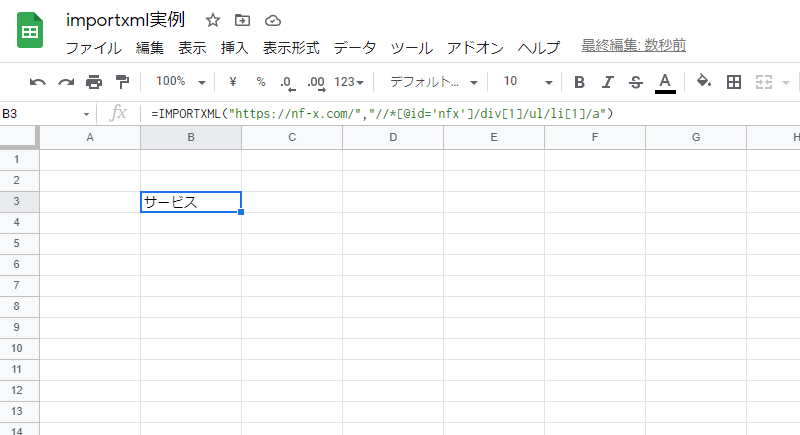
このようにして、「サービス」という文字をホームページからスクレイピングすることができました。
スクレイピングの注意点
ここまで、IMPORTXML関数を使ったスクレイピングについて説明しましたが、注意していただきたいことがあります。
大手サイトでスクレイピングができない
GoogleやAmazonなどは、IMPORTXML関数を使ってスクレイピングできません。
最近ではかなり規制が強化されており、GAS(Google Apps Script)やPythonなどでしかできないことが多いように感じます。
処理に時間がかかる
IMPORTXML関数を多用すると、サーバーに負荷をかけてしまうので関数がなかなか適用されないこともあります。
更に、IMPORTXML関数は2時間ごとに自動更新されるため、そのタイミングで表示されたりされなかったりとすることも。
なので、できるだけサーバーに負荷をかけない程度にしましょう。
html構造に依存する
IMPORTXML関数は一度適用させてしまえば、ずっとそのまま関数を入れっぱなしという方も多いかと思います。
しかし、対象サイトのhtml構造が変わってしまう、つまりホームページの改修やリニューアルなどがあった場合は気づかないうちに他の値になってしまったり、データが取得できないような状態になってしまうことも。
なので、スクレイピングしているから安心というわけではなく、定期的に状態を確認するようにしましょう。
【実例】IMPORTXML関数でスクレイピングをやってみよう
ここからは、実際にスクレイピングをやっていきます。
競合調査
よく他社サイトがどんな感じなのか、化粧品が欲しいけれど、どの化粧品がいいのか分析したいなど、用途は様々です。
今回は「佐賀 焼肉」と調べて出てきた上位3サイトをスプレッドシートにまとめます。
まずは、B列に検索結果のURLを貼ります。
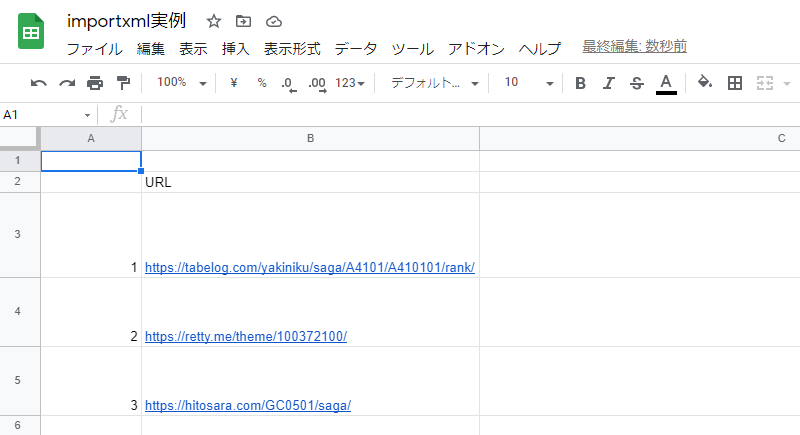
続いて、C列にタイトルを取得してみましょう。
ここでIMPORTXML関数を使います。
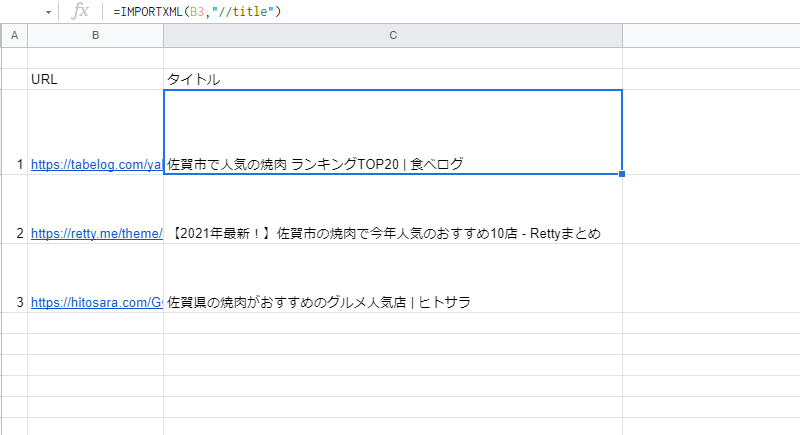
IMPORTXML(URL,”//title”)で、ページのタイトルが取れましたね。
もちろん、競合サイトをまとめるのであればこれだけでもよいのですが、もう少し具体的に一覧化して見たい場合は、詳細文(Description)も抽出してあげましょう。
詳細文の関数は、以下の通りになります。
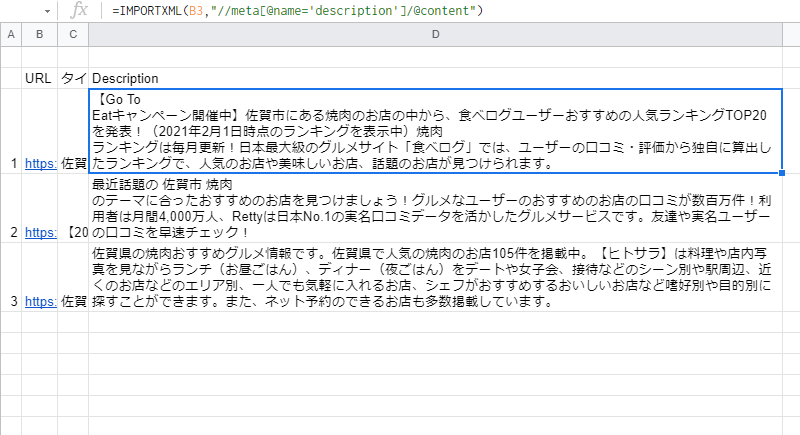
=IMPORTXML(URL、”//meta[@name=’description’]/@content”)
上記は一例であり、サイトの構造によってはうまく抽出できないこともありますので、ご了承ください。
このようにすることで、競合のタイトル・詳細文をスプレッドシートで一覧化し、より分析しやすくなるかと思います。
まとめ
今回は、IMPORTXML関数について説明しました。
少し前であれば、検索結果を表示させたり、Twitter・Instagramのフォロワー、Youtubeの動画タイトル取得などが容易にできましたが、2021年現在は従来の方法ではスクレイピングできないよう規制されています。
とはいえ、まだまだ業務に役立つ使い方は存在しています。
GASやPythonなど、プログラマーであれば使えないこともないでしょうが、プログラミングの知識がない方は、是非一度スクレイピングを常識の範囲内で使って業務を効率化してみてはいかがでしょうか?










